
Category Archives: Causal Inference

Cracking the Code: A Guide to Bambi’s Hierarchical Formula Syntax
I am learning Bayesian inference, currently working my way through the fantastic “Statistical Rethinking” book and implementing the code examples in PyMC. For someone who has spent years using the frequentist approach, thinking in probabilities is a real but rewarding challenge. To ease this transition, I decided to start with Bambi, a library that makes…
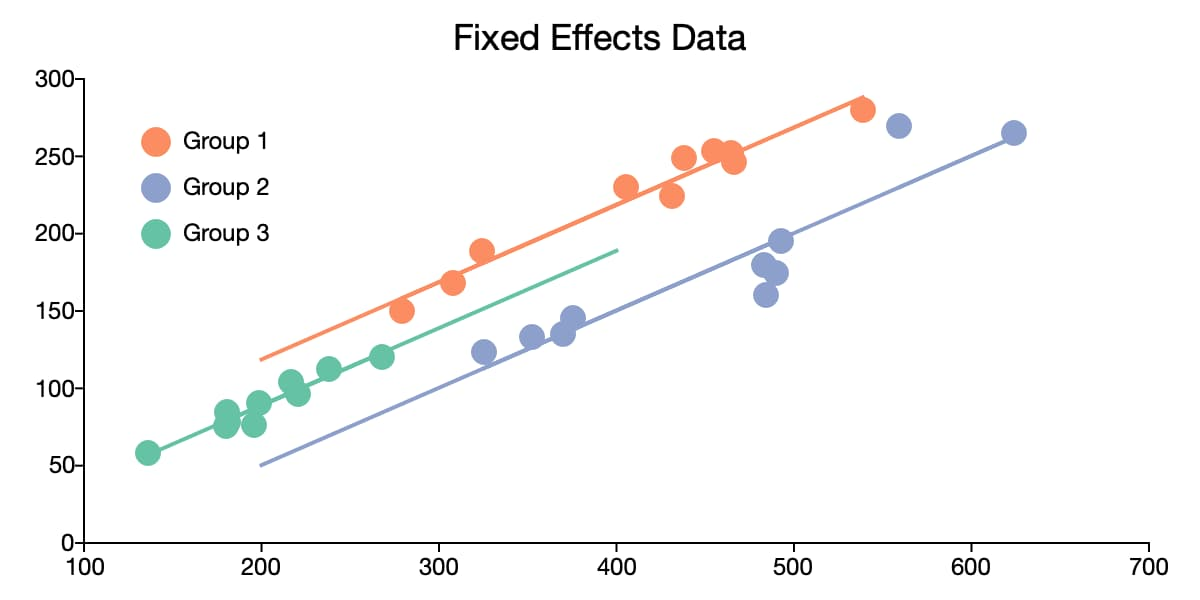
Unlocking the Power of Panel Data: A Beginner’s Guide with Python’s linearmodels
If you’re delving into data analysis, you’ve likely encountered cross-sectional data (data at one point in time) or time-series data (data over time for one entity). But what if you have data on multiple entities observed over multiple time periods? Welcome to the world of panel data! Panel data is incredibly powerful because it allows…

Double Machine Learning: Advancing Causal Inference with Machine Learning Techniques
Inspired by Brady Neal’s video where he humorously suggests that Double Machine Learning (DML) “is maybe twice as cool” as regular machine learning, we dive into this advanced causal framework. DML, also known as debiased machine learning or orthogonal machine learning, offers a robust method for causal inference by combining flexibility, low bias, and valid…
Doubly Robust Methods in Causal Inference: A Powerful Approach to Estimating Treatment Effects
In the world of causal inference, we’re constantly seeking methods that can provide accurate and reliable estimates of treatment effects. One approach that has gained significant traction in recent years is the family of Doubly Robust (DR) methods. These methods offer a unique combination of flexibility and robustness that make them particularly appealing for a…

Understanding S, T, and X Learners: Meta-Learners for Causal Inference
When estimating causal effects, we often want to go beyond average treatment effects and understand how treatments impact different individuals or subgroups. This is where meta-learners like S-Learner, T-Learner, and X-Learner come in handy. Let’s explore these powerful tools for estimating heterogeneous treatment effects, with a focus on intuition and practical implementation using the DoWhy…

Harnessing the Power of Text Embeddings for Causal Inference
In the evolving landscape of data science, researchers and practitioners are continually seeking innovative ways to handle complex data types. One such advancement is the use of text embeddings, a powerful technique that transforms text data into meaningful numerical representations. This blog post delves into the intricate world of text embeddings and explores how they…

Unveiling Double/Debiased Machine Learning (DML): A Practical Guide
Understanding the true effect of a variable (like a new medication or policy) on an outcome (such as health improvement or economic growth) can be challenging. Confounding variables—factors that affect both the treatment and the outcome—often complicate this task. Double/Debiased Machine Learning (DML) provides a powerful method to uncover these causal relationships, even in complex,…

Introduction to Testing DAG Validity: Local Markov and Edge Dependence Tests
In the realm of data science and causal inference, Directed Acyclic Graphs (DAGs) are powerful tools for modeling the causal relationships between variables. However, creating a DAG is only the first step. To ensure the accuracy and reliability of the causal inferences drawn from these models, we need to validate that the DAG accurately represents…